
OCR
Imagine que você quer digitalizar um artigo de revista ou um contrato impresso. Você pode passar horas digitando tudo de novo e corrigindo os erros – ou você pode usar o Software OCR. O que é OCR? OCR (Reconhecimento Ótico de Caracteres) é uma tecnologia que permite converter diferentes tipos de documentos, arquivos PDF ou imagens capturadas por uma câmera digital em dados editáveis e pesquisáveis. Nós gostaríamos de levá-lo aos bastidores do desenvolvimento e compartilhar algumas informações sobre esta tecnologia.
Qual é a precisão do nosso OCR?
A precisão dos resultados de OCR é normalmente medida em um nível de caracteres.
Por exemplo, 99% de precisão significa que 1 caractere de 100 (ou 10 em cada 1000) é reconhecido como “incerto”; 99,9% de precisão significa que 1 caractere de 1000 é reconhecido como “incerto”. Um “incerto” pode ser reconhecido como um caractere correto ou não, de modo que o julgamento final poderá ser feito apenas pelo usuário.
Quando a ABBYY ou outras empresas de OCR desenvolve e otimiza a tecnologia de reconhecimento, eles podem medir a precisão de reconhecimento resultante somente através de um determinado conjunto de amostras de imagens / documentos, com texto conhecido e 100% correto. Isso significa que na vida real se torna impossível uma medida absoluta, sendo que normalmente não há 100% de dados corretos.
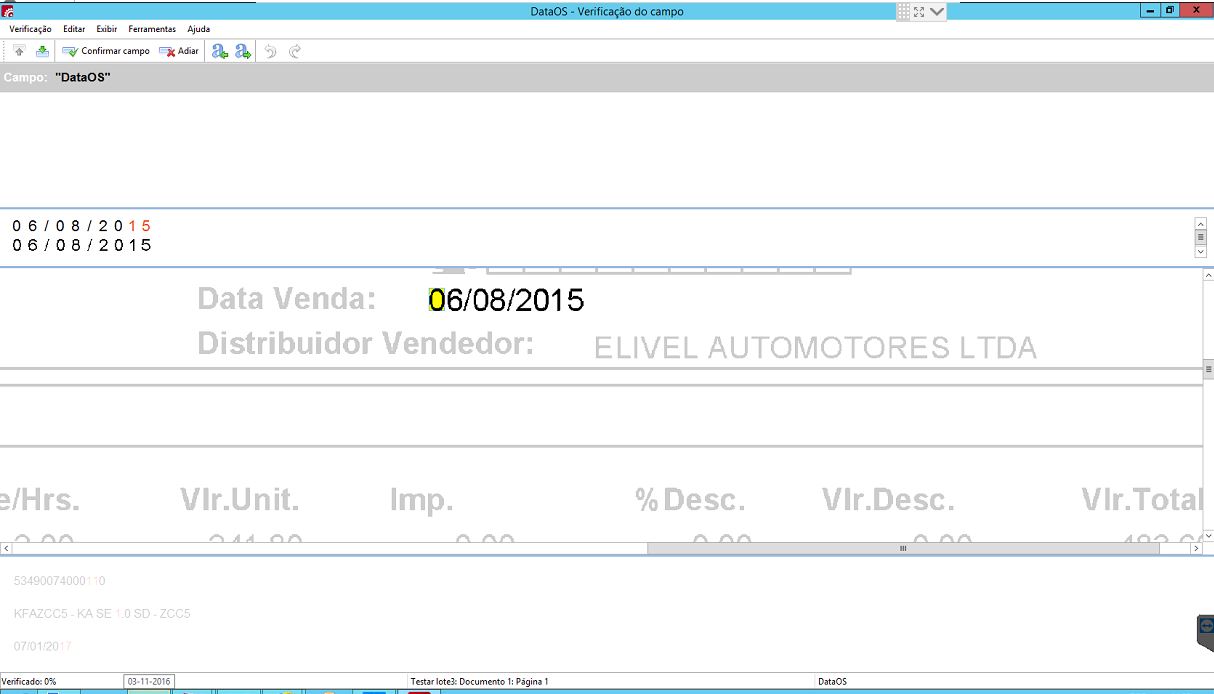
Estação de verificação
Para alfabetos latinos a precisão do OCR da ABBYY é de quase 100% para documentos de alta qualidade. Para as línguas que usam scripts complexos (por exemplo, árabe, chinês, malaio, etc.) a precisão é menor, mas ainda muito alta em comparação com outras alternativas.
A ABBYY fornece ferramentas de verificação especiais com a imagem original e o resultado do seu reconhecimento na mesma tela. O programa ajuda a comparar os resultados rapidamente e corrigir erros se houver algum.
Como obter uma melhor precisão de OCR?
A precisão de OCR totalmente depende de dois fatores:
1. Resolução de escaneamento, medida em DPI (pontos por polegada) – qualquer utilitário de escaneamento permite alterar esse parâmetro. Por padrão, qualquer software OCR requer resolução mínima de 300 dpi para alta precisão de reconhecimento. O OCR da ABBYY também é capaz de processar imagens em baixa resolução (mesmo com menos de 100 dpi), mas com expectativas modestas de precisão. Nos casos de textos de scripts complexos (chinês, japonês e coreano) ou árabe, a qualidade da resolução torna-se crítica devido à alta complexidade dos caracteres utilizados.
2. Qualidade do documento original. Se o documento for difícil para reconhecimento pelo olho humano (por exemplo, tamanho de fonte pequeno, tinta borrada, etc.), então os resultados de reconhecimento também serão ruins. Exemplo: se a cor da fonte do documento estiver próxima do fundo do documento ou se o plano de fundo for muito colorido, então, ao converter a imagem em preto-e-branco, as informações poderão ser perdidas.
Veja exemplos:

Exemplos
A ABBYY pode reconhecer texto manuscrito?
Existem 2 tipos de tecnologias de reconhecimento de texto: OCR (Reconhecimento Ótico de Caracteres) e ICR (reconhecimento inteligente de caracteres). OCR serve para o reconhecimento do texto impresso, enquanto o ICR ajuda a processar texto manuscrito (escrito em letras maiúsculas separadas como abaixo):

Nota: O ICR não processa a escrita cursiva como esta:
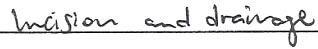
A tecnologia que pode reconhecer de forma confiável desse tipo de texto escrito à mão simplesmente não existe 🙂
Quais são as fontes suportadas pelo software da ABBYY?
A nossa tecnologia OCR é independente de fontes, sem trazer consigo qualquer “biblioteca de fontes”. A Abbyy usa uma aproximação humana – aborda e reconhece caracteres baseados em sua “forma”. Quando você vê fontes diferentes, você ainda entende cada letra, independentemente da fonte e o OCR da Abbyy faz o mesmo.
Para fontes complexas com caracteres especiais existe uma ferramenta útil chamada Formação de Padrão: você pega um texto impresso na fonte e treina o OCR para reconhecer esse específico tipo de caracteres. Você pode usar uma abordagem de 2 níveis: para treinar OCR Engine no nível de caractere e no nível de palavra. No final do dia, ele deve dar resultados muito bons durante o reconhecimento.
Nota: O treinamento do ABBYY OCR é viável quando as letras em uma palavra são separadas umas das outras e podem ser definidas uma da outra. Fontes “Designer”, no entanto, são muito difíceis de treinar e na prática, muitas vezes são capturadas como uma imagem.
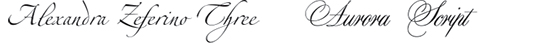
Parece curioso, não é? Agora você sabe o que é o OCR e quais peculiaridades se escondem no desenvolvimento dessa tecnologia.
Esse artigo foi copiado do Blog da ABBYY Brasil parceira oficial da Sesin Brasil. A Sesin é distribuidora oficial da ABBYY aqui no Brasil.
A Sesin Brasil junto com seus parceiros oferece uma gestão documental completa para pequenas, médias e grandes empresas através das suas soluções de GED/ECM. Você gostaria de saber mais a respeito ? Acesse este link, cadastre-se e iremos lhe apresentar a Sesin Brasil e a solução ao vivo.

